Мемоизация – часть так называемого “функционального подхода” в программировании, это паттерны и решения, призванные оптимизировать, ускорять и упрощать. Особенно в JavaScript.
Сейчас рассмотрим, как решить проблему с “медленной” функцией, и что такое мемоизация – забегая наперед, это интересная техника для обхода ненужной нагрузки на процессор и браузер. Будет рассмотрен пример “тормозящей функции”, и проблема будет решена, затем попробуем распространить решение на более общем примере. Посмотрим также, как мемоизация работает в распространенных JS-фреймворках.
Почему оно медленное
“Известный из университета (по идее) пример функции с серьезной потерей скорости. В Agile, числа Фибоначчи, или как еще называют Последовательность Фибоначчи (0,1,1,2,3,5,8,13…) часто применяется (с вариациями) для предварительной оценки сложности вычисления, и нагрузки на процессор. Как помните, серия цифр начинается с 0 и 1, далее каждая следующая цифра есть результат сложения двух предыдущих. 3=1+2, 5=2+3 и так далее. Можно сказать, что fibo(0)=0, fibo(1)=1, то есть для каждого n>1 fibo(n)=fibo(n-2)+fibo(n-1) – все очень просто. Пока что.
Цифры или числа Фибоначчи исторически означали "filius" Фибоначчи, или "сыновья Фибоначчи". Числами Фибоначчи в Европе называли числа вообще, как мы их сейчас понимаем, то есть арабские/индийские цифры. Именно Фибоначчи известен тем, что внедрил арабские цифры в Европе, то есть его стараниями проведена замена устаревшей и утомительной римской системы цифр (нагромождения букв, типа XIIIXCIMCVVVIII) на компактную "арабскую". Более современное понятие "чисел Фибоначчи", о котором идет речь в посте, происходит от решения им, Леонардо Фибоначчи, задачи о кроликах, стремительно размножающихся.
Это можно сделать в JavaScript при помощи рекурсии.
const fibo = (n) => {
if (n === 0) {
return 0;
} else if (n === 1) {
return 1;
} else /* n > 1 */ {
return fibo(n - 2) + fibo(n - 1);
}
};
Функция выглядит корректно, все хорошо, все прилично, однако… такой код будет очень медленным! Зададим же этой функции много значений n, как видим на графике. (Или в книге Mastering JavaScript Functional Programming). На графике видим экспоненциально растущее время выполнения функции – на вид простейшей!
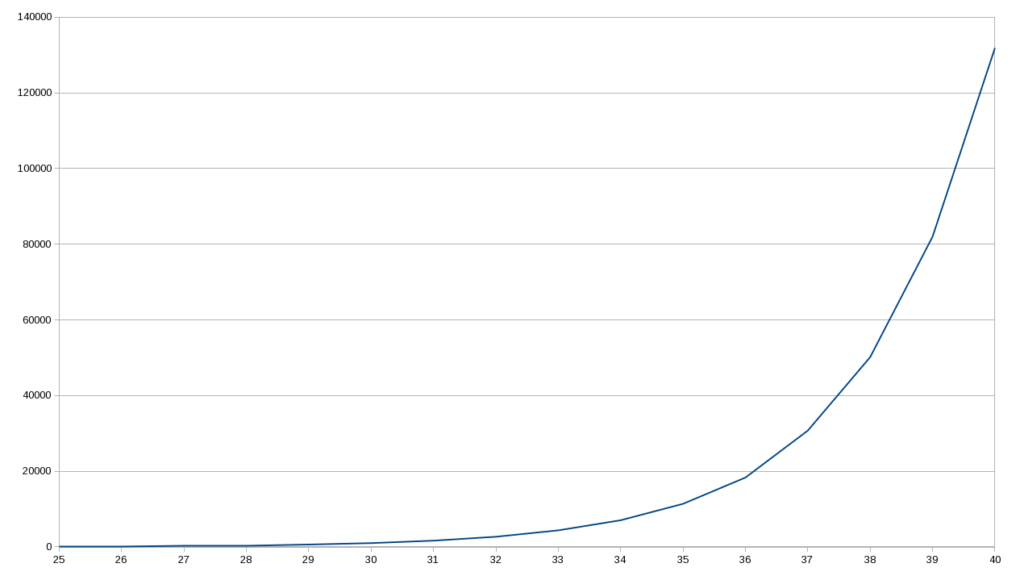
Чтобы понять, почему возникает такое замедление, давайте представим графически вызовы/переходы, которые осуществляются например при значении fibo(6). Это показано ниже. Даже при малом числе – 6, уже имеем достаточно разветвленное “дерево”. Многократно повторяемые – и ненужные – вызовы функции!
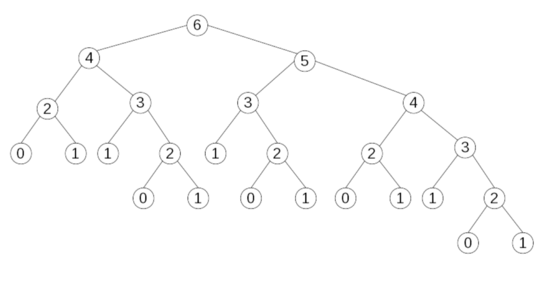
Проверим еще раз: один вызов для fibo(6) – отлично!, один для fibo(5) – отлично тоже! – но fibo (4) уже вызывается дважды, fibo(3) трижды, и еще больше раз для fibo(2), fibo(1) и fibo(0).
Сколько вызовов нужно, чтобы подсчитать fibo(n)? Назовем это calls(n). Calls(0)=calls(1)-calls(n-1): вызов fibo(n) плюс вызовы fibo(n-2) и fibo(n-1). Последовательность идет следующая: 1,1,3,5,9,15,25 (это вызовы в случае fibo(6)), 41, 67, 109, и так далее. Эти числа называются "числа Леонардо", их нельзя путать с "числами Фибоначчи" ибо это разные вещи; числа Леонардо - тоже названы в честь Леонардо Фибоначчи (а не да Винчи, как иногда ошибочно утверждают; то есть, одна последовательность названа в честь имени, а другая - в честь фамилии - одного и того же человека!).
Теперь ясно, что наш рекурсивный метод теряет много времени на выполнение уже однажды выполненной работы, ок, и что с этим сделать?
Частичное решение
Эта проблема достаточно частая. Например, в Динамическом Программировании (при оптимизации отдельных типов проблем) мы тоже имеем повторяющиеся вызовы (как наши числа Фибоначчи), где повторно выполняется одинаковая работа. Проблема решается пропуском повторяемых вызовов, путем переписывания части кода. Это делает функцию более сложной, и задействуется кэш.
const already_calculated = {};
const fibo = (n) => {
if (!(n in already_calculated)) {
if (n === 0) {
already_calculated[0] = 0;
} else if (n === 1) {
already_calculated[1] = 1;
} else /* n > 1 */ {
already_calculated[n] = fibo(n - 2) + fibo(n - 1);
}
}
return already_calculated[n];
};
Мы используем объект (already_calculated) как кэш. Каждый раз при вызове fibo(n), мы сначала проверяем, не производилось ли уже ранее это вычисление, то есть имеется ли оно уже в кэше. Если нет, то вычисляем результат и передаем его в кэш. Результат всегда возвращается из кэша: return already_calculated[n].
Это работает (желательно проверить самому сразу же), и скорость выполнения здорово растет, потому что если есть любые повторяющиеся рекурсивные вызовы, они чудесно разруливаются при помощи “подъема” значения из кэша. Но, есть несколько неприятных вещей в этом решении:
- нужно применять объект в глобальном кэше (already_calculated), но глобальные переменные, вообще-то, не очень хорошая идея
- мы должны модифицировать код функции для задействования кэша, а это всегда может привносить в код ошибки
- наша работа не масштабируемая: если мы должны оптимизировать несколько функций, нам понадобится больше глобальных переменных и больше изменений в коде
Идея работает, но нам нужно более универсальное решение, оптимально – не приносящее минусы указанные выше. Нашим ответом на проблему является так называемая мемоизация, прием из функционального программирования.
Первое общее решение
Наша задача: как избежать повторения множества медленных вычислений, которые мы уже выполняли. Мемоизация является приемом из функционального программирования, который может применяться в качестве так называемой “чистой функции“, то есть функции без “побочных эффектов”, она всегда выводит одинаковый результат если вызывается с одинаковыми аргументами.
Мемоизация функции создает новую функцию, которая будет внутри проверять кэш ранее вычисленных значений, и если нужный результат найден, он будет возвращен, без дальнейших действий. Если значение не найдено в кэше, вся нужная работа будет проведена, но перед возвращением исходной точке – результат будет сохранен в кэше (как в предыдущем разделе), и таким образом будет доступен для будущих вызовов.
Поскольку мы не хотим модифицировать свой изначальный код, понадобится написать функцию memoize(…). Она будет принимать любую общую функцию как аргумент, и создавать новую функцию, которая будет работать точно как оригинальная, но использовать кэш во избежание повторения уже выполненной работы. Такая функция может выглядеть приблизительно так:
const memoize = (fn) => {
const cache = new Map(); /* (1) */
return (n) => {
if (!cache.has(n)) { /* (2) */
cache.set(n, fn(n)); /* (3) */
}
return cache.get(n); /* (4) */
};
};
Наша функция memoize(…) – высшего порядка, поскольку она принимает функцию в качестве параметра, и возвращает новую функцию в качестве результата; это распространенная ситуация в Функциональном Программировании. Как выглядит возвращаемая функция? В строке 1 описывается cache map, и применение Map более оправдано, чем применение объекта как map; и переменная cache будет объединена вместе с возвращаемой функцией при помощи closure; здесь не нужны глобальные переменные!. Новая функция запускается проверкой в (2), если кэш уже содержит нужный результат; если нет, выполняется вычисление в (3) и результат передается в кэш. Во всех случаях, возвращаемое значение (4) идет прямо из кэша. Элегантно.
Это можно протестировать легко, следующим кодом:
const fibo = memoize((n) => {
if (n === 0) {
return 0;
} else if (n === 1) {
return 1;
} else {
return fibo(n - 2) + fibo(n - 1);
}
});
Обратите внимание, что это тот же код, что и ранее, но есть одно отличие, в том что мы “окружили” тело функции fibo() вызовом в memoize(). Если мы протестируем эту функцию, без разницы какое значение n пробовать, производительность всегда будет хорошей, и fibo(n) будет возвращаться быстро.
Вместе с тем, наше решение все еще не идеальное. Например, а что если оригинальная функция принимает два или три аргумента вместо одного? Нужно более общее решение.
Реально общее решение
Итак, что делать в случае функции с двумя и более параметрами? Трюк состоит в превращении аргументов функции в строку, которую мы передаем как ключ в нашу map. Это просто сделать с применением JSON.stringify в нашей новой версии memoize(…), примерно так:
const memoize = (fn) => {
const cache = new Map();
return (...args) => {
const strX = JSON.stringify(args);
if (!cache.has(strX)) {
cache.set(strX, fn(...args));
}
return cache.get(strX);
};
};
Это решение – достаточно общее, его можно применять во всех функциях, независимо от количества принимаемых параметров. Оно будет работать даже при переменном количестве параметров (если вчитаться в код, то понятно почему). Наша мемоизация достаточно эффективная, но если нужна мемоизация в коде, есть еще более улучшенная версия здесь на Github – fast-memoize, это самая быстрая версия мемоизации; если интересно, можно почитать подробнее о самой быстрой JS-библиотеке мемоизации.
Итак, проблема с производительностью решена, общим или более частным решением. Давайте перед тем как посмотреть, какие решения есть в Web-UI фреймворках на этот счет, разберем возможный баг.
Мониторинг фронтенда
Кстати, есть или нет проблема с производительностью, требуется или нет мемоизация, а все-таки стОит ознакомиться с такой вещью как OpenReplay – тулзом для мониторинга фронтэнда. Он “реплаит”, то есть проигрывает еще раз, все что делает пользователь на странице, и мониторит как страница ведет себя.
OpenReplay позволяет “повторно проигрывать узкие места”, группировать JS-ошибки, и в целом мониторить производительность. Отличное средство для современных фронтэнд-команд, вот прямая ссылка.
Неявная ошибка
Если вы внимательны, то уже могли заметить, почему не было написано примерно так? :
const betterFibo = memoize(fibo);
Здесь скрывается небольшая ошибка. Давайте посмотрим на это в действии. Сначала я запланировал некие вызовы на оригинальную, не-мемоизированную функцию fibo(). (Я не был достаточно внимателен с таймингом, и я не сделал замеры; далее видно, почему это неважно). Тайминги загрузки оказались следующими – заметьте, я вычислил fibo(45) дважды, и функция сработала с тем же таймингом. Нагрузка на процессор, быть может, чуть-чуть отличалась, но не сильно.
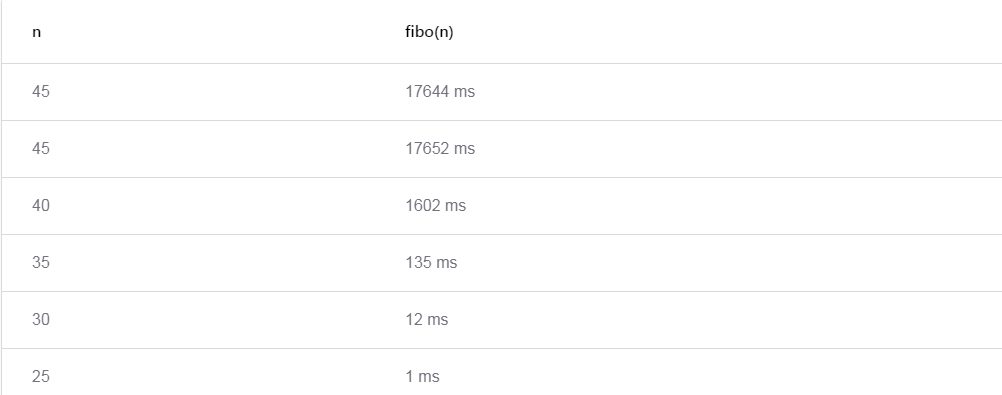
Я повторял тесты с мемоизированной функцией fibo(n), и они показали большое улучшение производительности, как и ожидалось. Первое вычисление заняло лишь 7 мс, и все другие – ничтожно малы, потому что все нужные значения уже были вычислены ранее, когда вычислялось fibo(45). Отлично, так и должно быть!
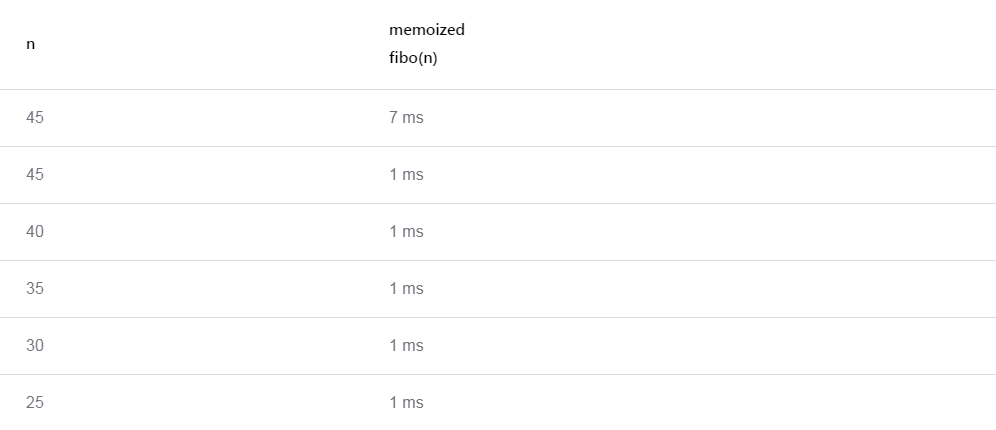
Далее я повторил тесты, но с применением betterFibo(n), и вдруг неожиданные результаты. Первый вызов забрал столько же времени, как оригинальная функция fibo(n)? Повторный вызов betterFibo(45) – довольно быстрый, потому что берется из кэша… однако! почему остальные вызовы такие медленные, все еще?
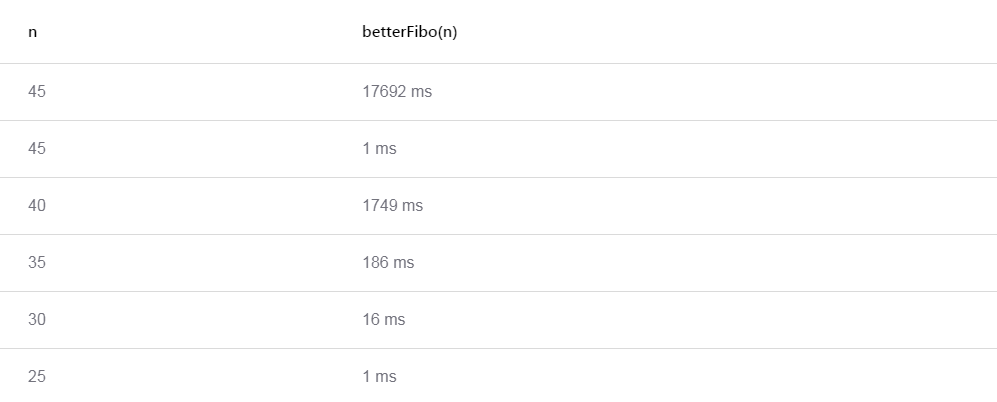
Проблема – важная, при этом ее легко упустить из виду. Дело в том, что betterFibo(n) вызывает оригинальную функцию fibo(n), а не мемоизированную. Результат для betterFibo(45) также идет в кэш (поэтому у нас оптимизируется 2-й ряд в схеме в начале статьи), но все другие вызовы fibo(n) – не кэшируются, и “логическая” производительность все так же плохая.
Что бы могло сработать здесь? Например, нечто вроде:
let fibo = (n) => {
if (n === 0) {
return 0;
} else if (n === 1) {
return 1;
} else /* n > 1 */ {
return fibo(n - 2) + fibo(n - 1);
}
};
fibo = memoize(fibo);
заметьте, там нет слова const в описании fibo(n).
Еще один способ который можно пробовать – задание fibo(n) “классическим способом”, без стрелочной функции.
function fibo2(n) {
if (n === 0) {
return 0;
} else if (n === 1) {
return 1;
} /* n > 1 */ else {
return fibo2(n - 2) + fibo2(n - 1);
}
}
fibo2 = memoize(fibo2);
Функция fibo2(n) работает просто отлично, потому что в JavaScript можно переопределить функцию. Однако, если используется ESLint, то будет ошибка, потому что переопределениефункций часто бывает причиной багов, и запрещено правилом no-func-assign.
Так мемоизация или отправка в кэш?
Надо быть внимательным, читая о мемоизации и кэшировании в документации по фреймворкам типа Vue или React. Потому что эти слова могут не значить в точности то, к чему вы привыкли. Например, в Vue вы вычисляете свойства, а в документации говорится, что “вычисляемые свойства кэшируются на основе их реактивных зависимостей, и будут изменяться, если некие реактивные зависимости изменены”. Таким же образом, в документации по геттерам в вычисляемых свойствах в Vuex упоминается, что “результат геттера кэшируется на основе своих зависимостей, и будет изменен, когда некие его зависимости изменятся”. Эти два упоминания не подразумевают мемоизацию; только Vue достаточно продвинутый по этой части, и не производит повторное вычисление уже вычисленного, если никакие из зависимостей не изменились. Если вычисляемое значение зависит от от атрибутов X, Y и Z, Vue не будет повторно производить вычисление, пока не изменится какое-либо значение X, Y, или Z. В то же время, Vue кэширует ранее вычисленное значение.
Та же проблема есть в React. В документации по хуку useMemo() сказано, что “useMemo будет проводить новое вычисление ранее мемоизированного значения, только если одна из зависимостей изменилась” – то есть это то же, что и в Vue, но это не мемоизация в точном смысле слова; здесь кэшируется одно ранее вычисленное значение. Далее, useCallback() делает аналогичное ограниченное кэширование; при этом ясно, что useCallback(fn, dependencies) эквивалентно useMemo(()=>fn, dependencies). И наконец, React.memo(…) тоже выполняет такую же простую оптимизацию, избегая перерисовки компонента, если его аргументы не изменились с прошлого вызова – но это, все-таки, не мемоизация во всей ее красе, это просто кэширование одного предыдущего вызова.
Итак
Итак, мы рассмотрели некоторые методы мемоизации, и наглядно убедились, что она ускоряет выполнение. При этом, ошибочно думать, будто мемоизация это нечто вроде волшебной палочки для всех проблем с производительностью; в неумелых руках она может даже ухудшить ситуацию! Учтите, что мемоизация подразумевает два дополнительных минуса: надо больше кэша для всех вычисленных значений; и надо больше времени для сверки этих значений, и вообще работы с кэшем. Если вы работаете с функцией, которая вызывается с одинаковыми аргументами редко (или вообще никогда), то мемоизация не принесет ничего хорошего; тогда лучше обойтись без мемоизации. Как и всегда, не надо делать “оптимизацию ради оптимизации”, подумайте сначала.
Решение, изложенное в статье, применимо для распространенных функций, а что насчет функций с активным вводом-выводом, типа API-вызовов? Можно пробовать применять мемоизацию для JS-промисов (promises), здесь может быть неплохая оптимизация.
И пусть ваш код всегда будет быстрым.”